
سرویس هوش درک زبانی یا همان لوییس (LUIS)، سرویسی شناختی به صورت API از شرکت مایکروسافت است که برای توسعهدهندگان، سرویسی را به منظور درک زبان طبیعی مبتنی بر یادگیری ماشین، ارائه می دهد. موارد استفاده زیادی برای لوییس وجود دارد، از جمله رابطهای زبان طبیعی مثل روباتهایی برای چت که آنها را چتبات (chatbot) مینامیم، رابطهای صوتی و موتورهای جستجو شناختی.
زمانی که ورودی کاربر به لوییس در قالب متنی است – به آن ٬سخن٬ (utterance) می گوییم- لوییس، قصد و هدفی که در ٬سخن٬ وجود دارد را تشخیص میدهد و آن را به عنوان خروجی، باز میگرداند. پس، لوییس میتواند به توسعه دهندگان کمک کند تا به صورت خودکار دریابند که کاربر میخواهد در مورد چه موضوعی سؤال بپرسد.
در این مقاله، تمرکز بر چگونگی افزایش درک، از ٬دادههای گفتگو٬ میباشد. منظور از ٬دادههای گفتگو٬ یعنی دادههایی که از توالی ٬سخن٬ها ایجاد شده که باعث شکلگیری یک گفتگو می شود.
در این مقاله مشاهده خواهیم کرد که چگونه دادههای گفتگو را تغییر شکل دهیم، یعنی با به کار گیری لوییس در هر ٬سخن٬ در یک گفتگو، دادههایی که ذاتاً ساختاری ندارند را به مجموعه دادههایی ساختیافته تبدیل کنیم. سپس از فرآیندکاوی بر روی مجموعه دادههای ساختیافته استفاده کنیم تا از گفتگوی اصلی، درکی به دست آوریم.
آماده کردن دادههای گفتگو برای فرآیندکاوی
به منظور نمایش گفتگوها به عنوان فرآیند، هر case ID متعلق به یک گفتگوی مشخص خواهد بود و منظور کاربر در ٬سخن٬ های مختلف، در هر گفتگو، به عنوان فعالیتهای فرآیند در نظر گرفته میشود.
در ادامه، مثالی از دادههای گفتگو آورده شده است. در این مثال، کاربران با چتبات در مورد وام مسکن گفتگو می کنند. برای سادگی در ارائه مثال، تنها ٬سخن٬ های کاربران آورده شده و پاسخهای چتبات نیست. میتوان هر نوع اطلاعات مرتبط دیگری که بخواهیم، مثل پاسخ چتبات یا دادههای کاربر و … را نیز اضافه کنیم.بر اساس هر ٬سخن٬، لوییس میتواند تشخیص دهد که کاربر در مورد چه موضوعی سؤال میپرسد. لوییس همچنین میتواند موجودیت های مختلف که اشاره به اشیاء واقعی دارد را نیز در هر ٬سخن٬ تشخیص دهد. به علاوه، لوییس به عنوان خروجی، برای هر قصد و موجودیتی که تشخیص میدهد، یک نمره اطمینان نیز اختصاص میدهد. این نمرات، در بازه ی ۰ تا ۱ خواهند بود، که ۱ نشان دهنده بیشترین میزان اطمینان در مورد تشخیص است و ۰ نشان دهنده کمترین.
در پشت صحنه، درواقع لوییس مدلهای یادگیری ماشین را به کار میگیرد تا بتواند منظور هر ٬سخن٬ و موجودیت ها را تشخیص دهد و میتواند با مثالهایی جدید، آموزش ببیند. این چنین مثالهایی به طور خاص مربوط میشوند به حوزه کاربری برنامه که توسعهدهنده قصد دارد بر آن تمرکز کند. این امکان به توسعه دهندگان اجازه میدهد که تشخیص منظور و موجودیتها را در هر ٬سخن٬ که کاربر می پرسد، شخصیسازی کنند.
در ادامه مثالی از خروجی لوییس آورده شده است که در آن بر اساس تعدادی از مثالهای مربوط به فضای برنامههای تکنولوژی مالی، شخصی سازی شده است. در این مثال، کاربران میتوانند سؤالاتی در مورد حسابهای بانکی خودشان یا تسهیلات مالی مثل وام مسکن سؤال بپرسند.
{
“query”: “what are annual rates for savings accounts”,
“topScoringIntent”: {
“intent”: “OtherServicesIntent”,
“score”: 0.577525139
},
“intents”: [
{
“intent”: “OtherServicesIntent”,
“score”: 0.577525139
},
{
“intent”: “PersonalAccountsIntent”,
“score”: 0.267547846
},
{
“intent”: “None”,
“score”: 0.00754897855
}
],
“entities”: []
}
همانطور که در مثال می بینید، لوییس در خروجی ها، بر اساس ورودیها، منظور هر ٬سخن٬ را به همراه نمره اعتماد نشان می دهد. در این مثال همانطور در بقیه مقاله هم به آن اشاره شده است، تمرکز فقط بر منظور هر ٬سخن٬ میباشد و به تشخیص موجودیت نمیپردازیم.
قصدهای زیر در دادهها گنجانده شده اند:
- قصد احوالپرسی: آغازکننده گفتگو
- قصد تحقیق: ٬سخن٬ عمومی به منظور تحقیق از جانب کاربر
- قصد درخواست اپراتور: درخواستی از جانب کاربر به منظور صحبت با اپراتور انسانی
- قصد سؤال مشخص: سؤال کاربر در مورد نرخ وام
- قصد اطلاعات تماس: ارائه اطلاعات تماس توسط کاربر
- قصد نظردهی مثبت: نظری مثبت از جانب کاربر ارائه شود
- قصد نظردهی منفی: نظری منفی از جانب کاربر ارائه شود
- قصد اتمام گفتگو: اتمام گفتگو با ربات،با درخواست اولیه از جانب کاربر
برای پنج رخداد در گفتگو با شناسه ConversationId 3 که در مثال اول مقاله، آورده شد، منظورهای زیر برای هر ٬سخن٬ تشخیص داده شد:
- قصد تحقیق
- قصد سؤال مشخص
- قصد نظردهی مثبت
- قصد اطلاعات تماس
- قصد اتمام گفتگو
به این روش، دادههای گفتگو اصلی، به یک توالی از منظورها، تغییر شکل داد. این نتیجه برای غنی سازی مجموعه داده اصلی در قالب ستون چهارمی با عنوان ٬قصد٬ (Intent) استفاده خواهد شد.
زمانی که این مجموعه داده را با وجود ستون چهارم (٬قصد٬) وارد یک نرمافزار فرآیند کاوی میکنیم (در این مثال، از نرمافزار Disco استفاده شده است)، ویژگیهای فایل مجموعه داده به شکل زیر تنظیم میشود:
- ConversationId: گفتگوها را به روشی یکتا، شناسایی میکند و معادل case ID است.
- TimeStamp: زمانی که برای یک جفت از ConversationId و ٬سخن٬ استفاده می شود، کارکردی، معادل زمان در فرآیندکاوی دارد.
- Utterance (٬سخن٬): سخن کاربر(اساسا یک داده متنی غیرساختیافته) که لوییس بر آن اعمال میشود تا قصدها را که به عنوان یک ویژگی وارد شدهاند، شناسایی کند.
- Intent (قصد): قصدی که لوییس تشخیص می دهد، معادل نام فعالیت در فرآیندکاوی است.
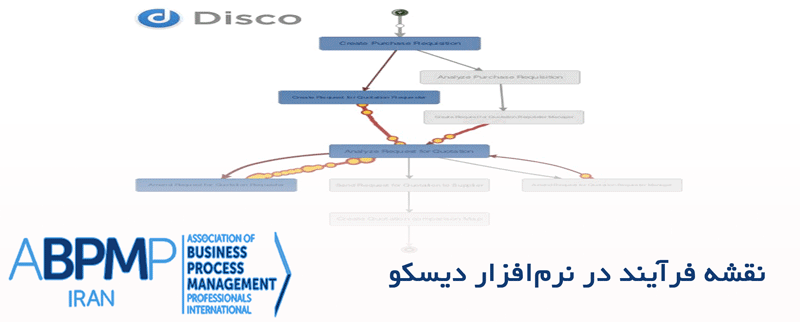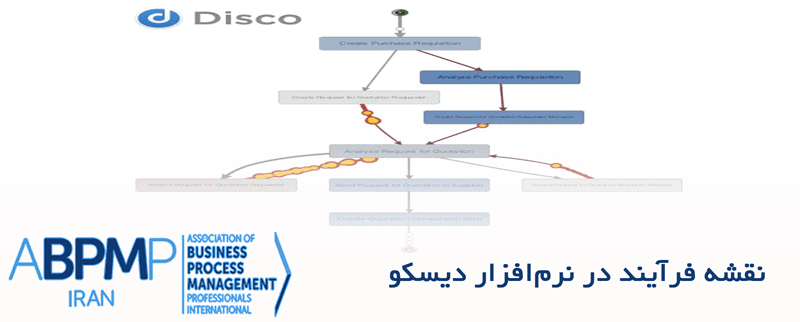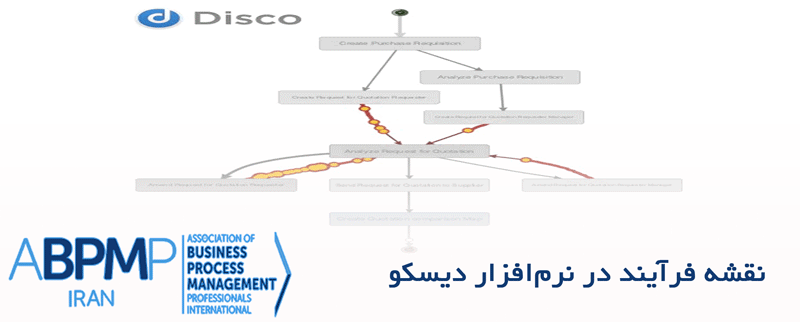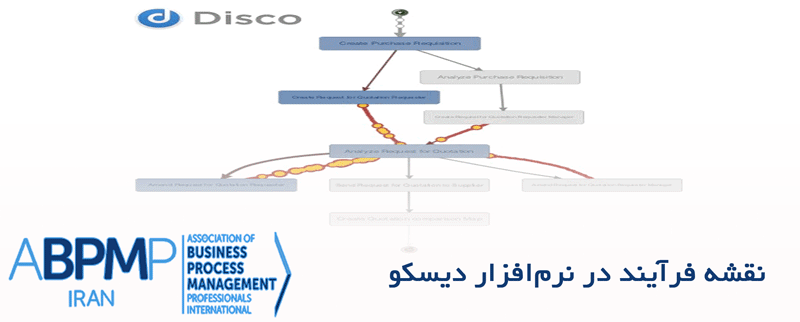
اعمال فرآیندکاوی بر دادههای گفتگو با استفاده از نرمافزار Disco:
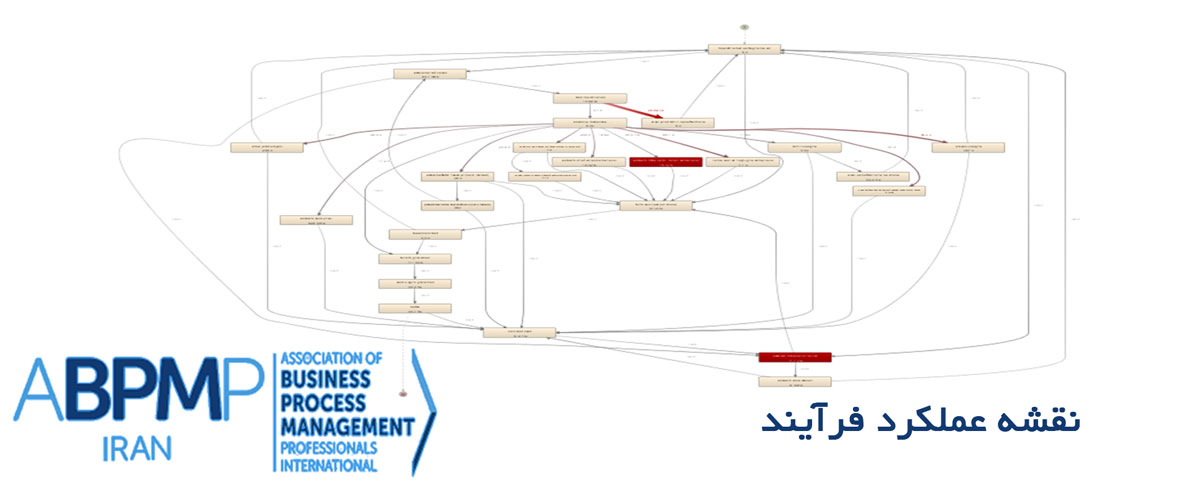
پس از آنکه فایل CSV را بر اساس تنظیماتی که در بالا نشان داده شد، وارد نرمافزار Disco کردید، میتوانید نقشه فرآیند حاصل را که مبتنی بر دادههای گفتگو است، مشاهده کنید.
نقشه فرآیند، یک نمایش گرافیکی از جابهجایی های مختلف بین رخدادها در فرآیند و میزان فراوانی و تکرار فعالیتهای مختلف است. در مجموعه داده مورد استفاده در این مثال، جابهجاییهایی که نشان داده شدهاند، مربوط به جابهجایی بین ٬قصد٬ ها هستند.بر اساس نقشه فرآیند حاصل، میتوانیم یک شمای کلی از گفتگو به دست آوریم و ببینیم که گفتگوها میتوانند به یکی از سه حالتی که در نقشه می بینیم، آغاز شوند. اکثر گفتگوها با قصد اتمام گفتگو تمام می شوند، اما تعدادی دیگر از گفتگوها با ٬قصد٬های دیگر که نشاندهنده احوالپرسی یا نظردهی منفی است،تمام می شوند. ما به طور خاص، به نظردهی منفی اهمیت می دهیم، چرا که میتواند به مواردی خارج از حدود گفتگو اشاره کند که نیاز به توجه بیشتری دارند.
به علاوه، جابهجاییهای بین ٬قصد٬های مختلف، همچنین میتواند اطلاعات بسیار ارزشمندی را در نتیجهگیری از ٬قصد٬ها، ارائه دهد. برای مثال، ممکن است بتوانیم تعیین کنیم که آیا ٬سخن٬ یا ٬قصد٬ مشخصی وجود دارد که منجر به ٬قصد٬ برای بیان نظر منفی می شود. این چنین نتیجهای اهمیت دارد، چرا که باعث میشود تا گفتگوها از این مسیر خارج شوند.
اطلاعات در مورد تکرار ٬قصد٬ها و ٬جابهجایی٬ ها، به عنوان بخشی از نقشه فرآیند موجود، در دسترس است. به طور خاص، میتوانید دو٬قصد٬ رایج را مشاهده کنید که بیشتر از بقیه تکرار شدهاند و آن دو ٬قصدسوال مشخص٬ و ٬قصد اتمام گفتگو٬ است و جابهجایی از مورد اول به مورد دوم، خیلی رایج است. این نتیجه، یک خلاصه مفید را در یک نگاه و بر اساس محتوای گفتگو ارائه می دهد.
این جریان، همچنین میتواند موقعیتی را ارائه دهد که گفتگوها با توجه به جزیئات بیشتر بین ٬قصد سؤال مشخص٬ و ٬قصد اتمام گفتگو٬، تقویت شوند و بهبود یابند و این جریان را به ٬قصد٬های بهتر که میتواند ابعاد واضحتری از تعامل کاربر را نشان دهد، منجر شود. این جریان باید با شخصیسازی و آموزش مجدد لوییس انجام شود و فرآیندکاوی را بر اساس دادههای گفتگوی جدید، دوباره تکرار کنیم.
وقتی که به وضعیت کلی آمار نگاه می کنیم، میتوانیم فهمی از زمان گفتگو نیز به دست آوریم. این موضوع، در تشخیص موارد خارج از حالت عادی، مفید است، مواردی که در آن گفتگو بسیار کوتاه است و بررسی متقابل با گفتگوها در نقشه، نشان میدهد که گفتگوها به صورت بالقوه، مشکل داشته اند. همچنین میتواند به تشخیص گفتگوهایی با مدت زمان بیشتر منجر شود. در مثال این مقاله، این چنین گفتگوهای طولانی، احتمالاً گفتگوهای موفقیتآمیزی خواهند بود.به منظور عمیقتر شدن در گفتگوهایی که رفتارهای جذابی از خود نشان می دهند،مثلا به طور غیرمعمولی مدت گفتگو کوتاه یا بلند است،یا گفتگوهایی با ساختارهایی از ٬قصد٬های مشخص، میتوانیم از امکان فیلترگزاری استفاده کنیم(نرم افزار Disco این امکان را دارد). در هر لحظه، نرمافزار Disco این امکان را میدهد تا بر کل مجموعه داده و با ابعاد متفاوت، فیلترگزاری کنیم.
این امکان کمک میکند تا الگوهای رایج در گفتگوهای فیلتر شده را شناسایی کنیم.
همچنین میتوانیم با استفاده از بخش فعالیتها در نمایش آماری، تا حدودی آمار کلی در سطح ٬قصد٬ها را به دست آوریم. در مثال پایین مشاهده میکنید که نظردهی منفی، تنها ۳ درصد کل ٬قصد٬ها را در گفتگوها تشکیل داده است.در نهایت، میتوانیم بر هر یک از گفتگوها به صورت جداگانه و بر اساس متغیرهایشان نگاه کنیم. با یک متغیر، تمام گفتگوها که جریان گفتگوی مشابهی از ٬قصد٬ها را دارند، در یک گروه قرار میگیرند و میتوانیم متغیرهای متفاوتی را جستجو کنیم تا ببینیم که آیا آنها متناسب با سناریوهای پیشبینی شده هستند یا خیر.
برای مثال، در عکس پایین، میتوانید یک گفتگوی بهخصوص را که متعلق به متغیری از ۲ ٬قصد٬ است را مشاهده کنید:
٬قصد سوال مشخص٬ و ٬قصد اتمام گفتگو٬. با مقایسه گفتگوهایی که ساختارهایی مشابه دارند، میتوانید یادبگیرید که آیا الگوهایی وجود دارد که میتوان آنها را انتخاب کرد تا به موفقیتآمیز بودن گفتگو کمک کند یا خیر. اگر تفاوتهای پیشبینی نشدهای پیدا کردید، احتمالاً به شما میتواند کمک کند تا دلیل آن را پیدا کنید.
ترجمه و تنظیم: ادیب ضیایی

بدون دیدگاه